SQL SELECT 구문의 GROUP BY절
24 Jun 2017GROUP BY
- 테이블의 레코드를 grouping하기 위해 사용된다.
- 해당 절은 각각의 그룹에 대해 하나의 행을 만드는데 이 과정을 aggregation이라 부른다.
- GROUP BY는 주로 aggregate function(COUNT, MAX, MIN, SUM, AVG)와 함께 쓰인다.
- 1개 이상의 column에 대해 grouping할 수 있다.
- SELECT 절에는 GROUP BY에 쓰인 column만 사용가능하다.
GROUP BY를 실행시하기 위해 기본적으로 간단한 테이블 및 샘플 데이터를 만들었다.
DROP TABLE IF EXISTS Person;
CREATE TABLE IF NOT EXISTS Person(
id SERIAL PRIMARY KEY,
name varchar(40) NOT NULL,
age int NOT NULL,
money int NOT NULL,
gender bit(1) NOT NULL,
city varchar(20) NOT NULL
);
INSERT INTO Person(
name, age, money, gender, city)
VALUES
('Junkyu Park', 27, 50000, b'0', 'Ulsan'),
('Sangheon Lee', 27, 3000000, b'0', 'Ansan'),
('Taesung Kim', 27, 40000, b'0', 'Daegu'),
('Dohyung Kim', 22, 55000, b'0', 'Sokcho'),
('Sangwook Nam', 27, 40000, b'0', 'Seoul'),
('Nayoung Kim', 25, 60000, b'1', 'Seoul'),
('Jaeik Lee', 27, 5000, b'0', 'Seoul'),
('Daeho Lee', 29, 3400000, b'0', 'Seoul')
;
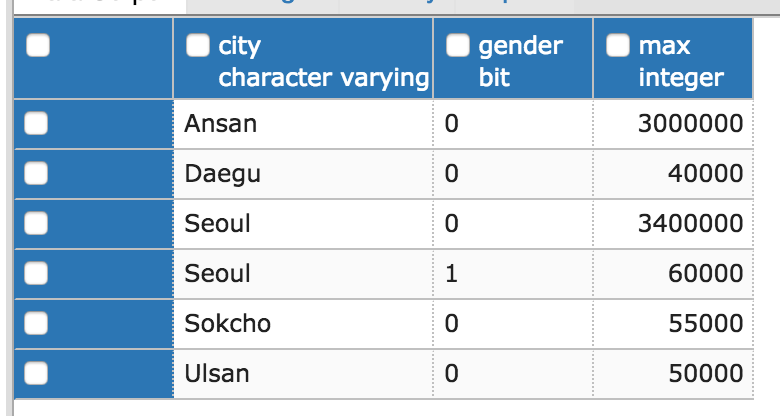
SELECT * from Person;
전체 데이터
위의 테이블은 한 개개인의 정보를 담고 있는 테이블이며 그사람의 이름, 나이, 가진 돈, 성별(0;남자, 1;여자), 살고있는 도시를 저장하고 있다.
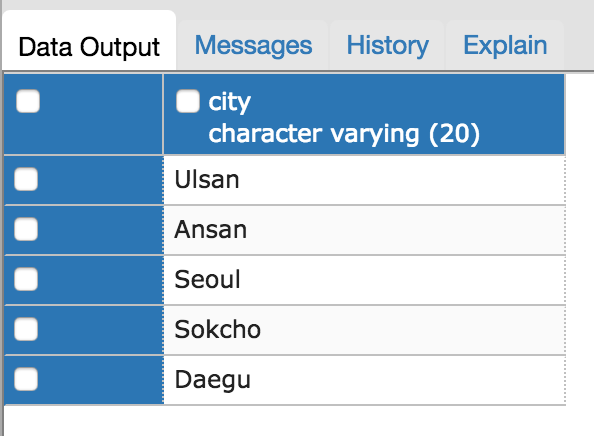
SELECT Person.city from Person
GROUP BY Person.city;
여기서 GROUP BY를 통해 city column을 그룹핑하면 city가 같은 데이터들을 하나의 데이터로 묶어버린다.
여기서 SELECT 절에 GROUP BY에 명시되 있지않은 column을 추가하면 에러가 발생한다.
SELECT Person.city, Person.name from Person
GROUP BY Person.city;

GROUP BY를 집계함수와 함께 사용할 수 있다.
SELECT Person.city, SUM(Person.money) from Person
GROUP BY Person.city;
이 쿼리는 같은 도시에 살고있는 사람들을 그룹핑한다음에 그 도시에 사는 사람들이 가진 돈의 총합을 구하는 쿼리다.
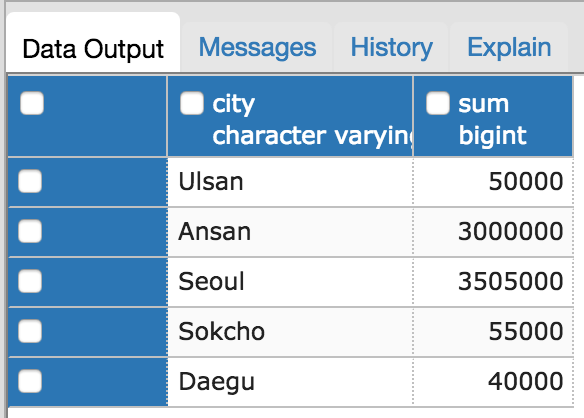
전체 데이터중 서울에 사는 사람은 총 4명(Sangwook Nam, Nayoung Kim, Jaeik Lee, Daeho Lee)이고 이들이 가진 돈의 총합을 구하면
40000 + 60000 + 5000 + 3400000 = 3505000이다.
그리고 각 도시에서 가장 돈을 많이 가진 사람은 얼마를 가지고 있는지를 알아보고 싶다.
SELECT Person.city, MAX(Person.money) from Person
GROUP BY Person.city;
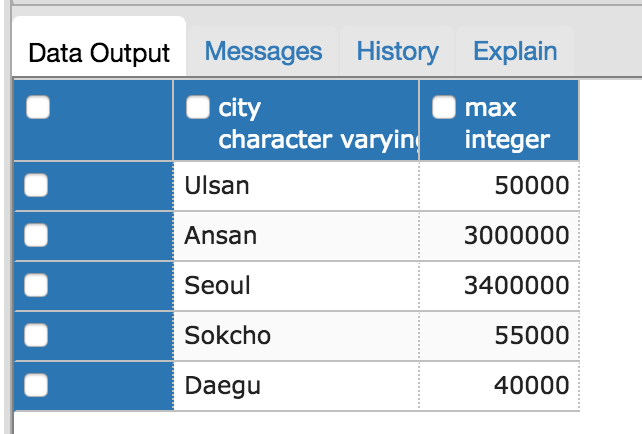 서울에 살고 있는 사람중 돈이 가장 많은 사람은 Daeho Lee이고 3400000원을 가지고 있다.
서울에 살고 있는 사람중 돈이 가장 많은 사람은 Daeho Lee이고 3400000원을 가지고 있다.
aggregate functions중에서 SUM, MAX, MIN, AVG의 경우에는 column의 데이터 타입이 숫자인 경우에만 가능하다.
GROUP BY의 아래에는 ORDER BY절을 사용할 수 있고 오름차순은 ASC, 내림차순 출력을 원하면 DESC 키워드를 사용하며 디폴트는 오름차순이다.
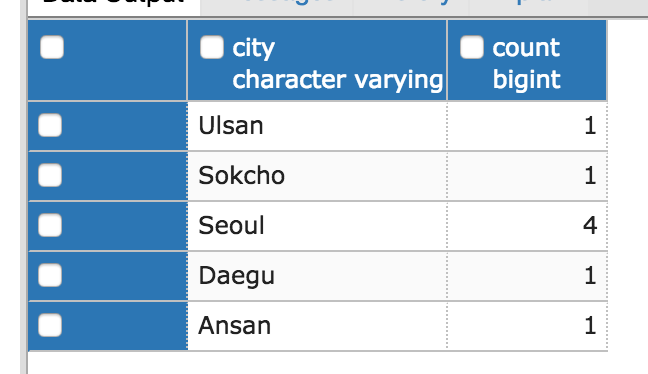
SELECT Person.city, COUNT(*) from Person
GROUP BY Person.city
ORDER BY Person.city DESC;
또한 GROUP BY에는 HAVING 절을 사용할 수 있는데,
GROUP BY로 집계한 데이터의 조회 조건을 줄 수 있다.
사람들이 살고 있는 도시와 그 도시에 살고 있는 사람들의 수를 출력하는데, 이때 전체 데이터에서 그 도시에 살고 있는 사람의 수가 4명 이상인 도시와 사람의 수를 출력하고 싶다.
SELECT Person.city, COUNT(*) from Person
GROUP BY Person.city
HAVING COUNT(*) >= 4;

사람이 1명 이상 살고 있는 도시에 대해 출력할 때 사람이 많이 사는 순서(내림차순)대로 출력하고 싶다면 GROUP BY 밑에 order by를 쓴다.(having을 group by와 order by 밑에 쓰면 에러발생)
SELECT Person.city, COUNT(*) from Person
GROUP BY Person.city
HAVING COUNT(*) >= 1
ORDER BY COUNT(*) DESC;
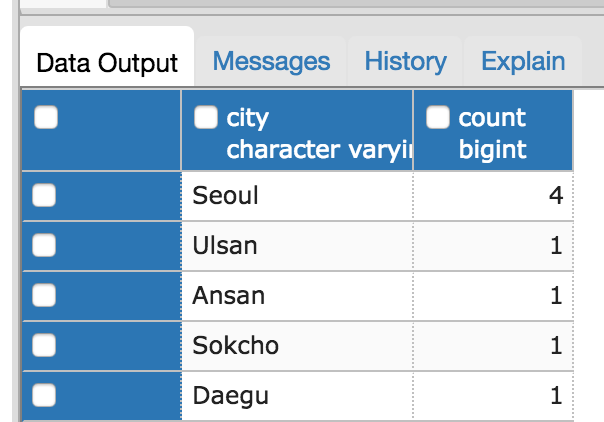
HAVING에 대해서 다시 살펴보면, 도시로 GROUP BY된 데이터중 도시명이 S로 시작하는 도시와 그 도시에 살고 있는 사람의 수를 출력하는 쿼리를 GROUP BY, HAVING을 통해 표현하면 다음과 같다.
SELECT Person.city, COUNT(*) from Person
GROUP BY Person.city
HAVING Person.city LIKE 'S%';
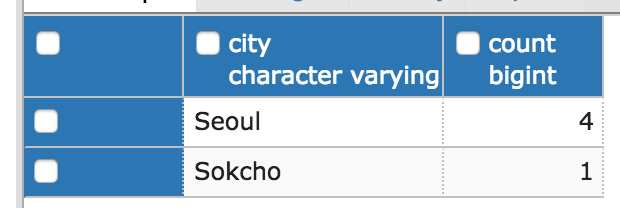
이 HAVING 조건을 WHERE로 바꾸면 다음과 같고 같은 결과를 반환한다.
SELECT Person.city, COUNT(*) from Person
WHERE Person.city LIKE 'S%'
GROUP BY Person.city;
위의 HAVING 조건이 자동으로 WHERE로 변경되어 쿼리가 실행된다고 하는데, 상황에 따라 자동 변경이 안될 수도 있기에 가능하면 WHERE에 조건을 넣어주는 게 좋다고 한다.
또한 GROUP BY에 두개 이상의 column을 넣을 수도 있다.
다음은 각 도시와 성별을 그룹으로 묶고, 각 도시별 남성, 여성중에 돈을 가장 많이 가진 사람이 얼마나 가지고 있는지를 출력하는 쿼리이다.
SELECT Person.city, Person.gender, MAX(Person.money) from Person
GROUP BY Person.city, Person.gender;